
Automated discovery is a software-driven process where tools continuously scan, identify, and classify data, devices, or documents across systems to maintain current, actionable inventories without manual effort. For attorneys and paralegals, understanding how automated discovery works is the difference between spending weeks sifting through case files and completing the same work in hours. The technology draws from disciplines like IT network management and process mining, but its application in legal workflows is now reshaping how criminal defense teams, civil litigators, and compliance professionals handle evidence. Platforms like Caseflow, SAP Signavio, and Oracle have each demonstrated that automation reduces both processing time and human error at scale.
How automated discovery works: the technical workflow
Automated discovery functions by executing a structured pipeline of scanning, identification, classification, and storage. Automated tools scan network IP ranges using methods such as ping sweeps, ICMP protocol checks, ARP scanning, and port probing to locate reachable systems and collect metadata including IP address, hostname, and device type. In legal contexts, the same logic applies to document repositories, case management systems, and custodian data stores. Instead of IP addresses, the system catalogs file types, custodian names, date ranges, and document metadata.
Oracle's enterprise architecture illustrates how this scales. The Oracle discovery pipeline uses microservices including a Discovery Service, poller coordinators, DOM Processor, and Graph Sink to manage jobs via REST API calls, poll devices periodically, and normalize data for topology mapping. Large-scale automated discovery requires this kind of orchestration, separating job management, polling, and data processing for reliability. Legal teams running discovery across thousands of documents benefit from the same architectural principle: parallel processing keeps the system fast while maintaining accuracy.

A critical design pattern in high-performance discovery systems is the separation of fast indexing from full record retrieval. Layered discovery steps use quick metadata filters to identify candidates first, then trigger slower, detailed record retrieval only for relevant items. This optimizes large dataset processing by narrowing candidates before full evaluation. For a criminal defense attorney reviewing body camera footage, police reports, and lab results, this means the system surfaces the most relevant materials first rather than forcing a linear review.
| Discovery method | Primary input | Data collected | Legal parallel |
|---|---|---|---|
| IP range scan / ping sweep | Network address space | IP, hostname, device type | Custodian list, file server inventory |
| Protocol-based discovery (SNMP, ARP) | Device responses | Service metadata, OS type | Document format, application source |
| Scheduled polling | Time-triggered jobs | Change logs, new resources | Updated custodian data, new filings |
| Metadata indexing | File headers, tags | Author, date, file type | Exhibit classification, date filtering |
Pro Tip: When configuring a discovery job for a legal matter, treat custodian accounts and shared drives the same way IT teams treat IP ranges. Define the scope explicitly before the first run to avoid pulling in irrelevant data that inflates review volume.
What are the main types of automated discovery?
Three distinct variants of automated discovery apply directly to legal practice: network discovery, process discovery, and data discovery. Each operates on different inputs and produces different outputs, but all three reduce the manual labor required to maintain accurate, current information.
Network and device discovery maps assets across an infrastructure. Centreon's auto discovery module runs scheduled discovery rules with monitoring connectors, produces lists of detected resources, and can automatically add or disable resources without manual action. For legal teams, the equivalent is maintaining a live inventory of all data sources tied to a case, including cloud storage accounts, mobile devices, and third-party platforms.
Automated process discovery takes a fundamentally different approach. SAP Signavio's process discovery uses logs from ERP and CRM systems combined with AI to reconstruct actual process execution, revealing real workflow variants and inefficiencies. AI groups process variants, detects anomalies, and helps prioritize improvement areas by analyzing event data and user interactions. This shifts understanding from documented procedures to what actually happened, which is exactly what attorneys need when reconstructing a chain of events from digital evidence.
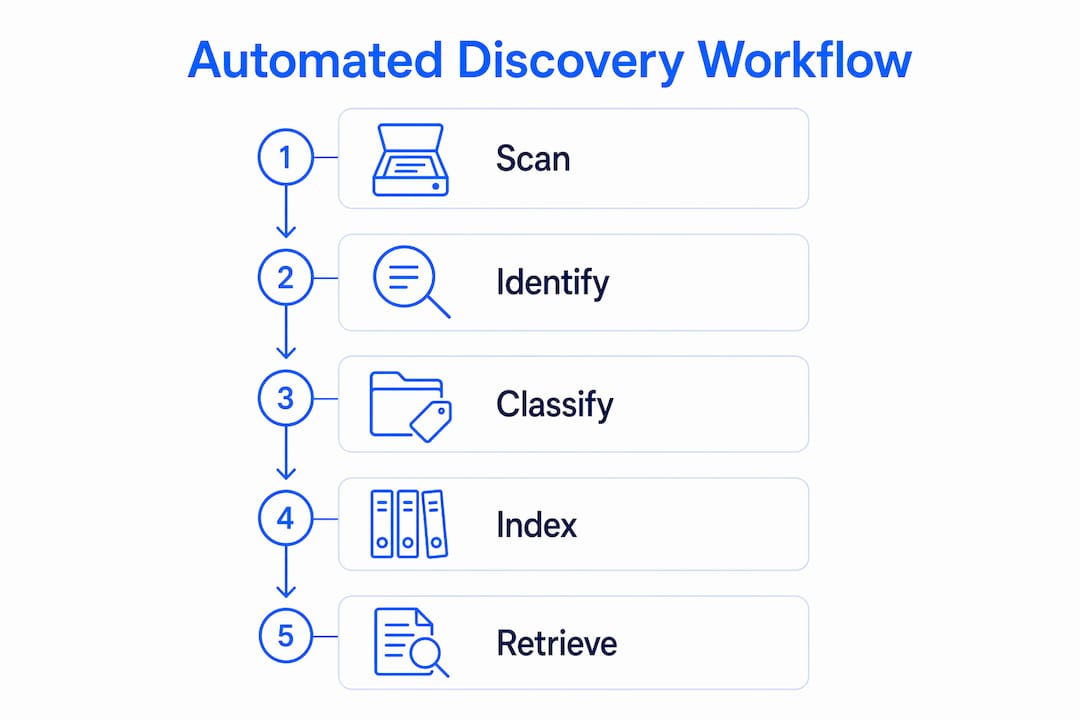
Automated data discovery continuously monitors sensitive or regulated data including personally identifiable information (PII) and protected health information (PHI). This variant is most directly relevant to legal compliance work, where attorneys must identify which documents contain privileged content, which include client data subject to confidentiality rules, and which fall under specific regulatory frameworks.
The contrast with manual discovery is stark:
- Manual review requires a paralegal to open, read, and tag each document individually, a process that scales poorly beyond a few hundred files.
- Automated discovery classifies thousands of documents simultaneously using predefined rules and AI models.
- Manual processes create static snapshots that go stale as new evidence arrives.
- Continuous or scheduled discovery keeps inventories current, automatically detecting newly connected or removed data sources during ongoing legal cases.
- Automated systems produce audit trails by default, while manual processes depend on individual note-taking discipline.
What are the benefits and challenges of automated discovery in legal practice?
The benefits of automated discovery for legal professionals are concrete and measurable. Time savings are the most immediate: tasks that previously required days of paralegal hours compress into automated runs that complete overnight. Continuous updates mean that when a client produces additional documents mid-case, the system incorporates them without requiring a full manual re-review. Reduced human error matters especially in criminal defense, where a missed Brady material disclosure can have serious consequences for both the case and the attorney's professional standing.
The challenges are equally real, and legal professionals must approach them with the same rigor they apply to any evidentiary question. Work product protection under FRCP 26(b)(3) extends to AI-assisted discovery tools, but court decisions like Morgan v. V2X establish that names of AI platforms may need disclosure depending on context. This means the specific tools you use are not always shielded from opposing counsel's inquiry. Attorneys must understand what their platforms do and be prepared to explain the methodology.
"Automated discovery tools must be governed with explicit scopes and scheduled runs. Without defined parameters, systems drift into collecting data outside the intended custodian set, creating defensibility problems that are difficult to correct after the fact."
Confidentiality is a second pressure point. When discovery data passes through third-party AI platforms, attorneys must verify that client communications and privileged documents are handled under appropriate data agreements. Governance controls and policy-driven configurations using defined scopes and scheduled jobs are the standard method for preventing scope drift and maintaining defensibility. Legal teams should treat discovery configuration as a legal document in its own right, not a technical afterthought.
Pro Tip: Before running any automated discovery tool on a client matter, review the platform's data processing agreements and confirm that attorney-client privileged materials are excluded from any training data or external processing pipelines. Caseflow's security practices address this directly for criminal defense workflows.
How to implement automated discovery in your legal practice
Adopting automated discovery methods requires deliberate setup, not just software installation. The following steps reflect best practices drawn from both IT discovery frameworks and legal workflow requirements.
- Define scope and parameters first. Identify custodians, relevant date ranges, file types, and data repositories before running any discovery job. Scope creep is the most common source of defensibility problems in automated discovery.
- Configure and test discovery rules. Build classification rules that reflect the specific legal matter: privilege keywords, relevant parties, document types, and jurisdictional requirements. Run a test pass on a small sample before full deployment.
- Schedule continuous refreshes. Set discovery jobs to run on a defined cadence, daily or weekly depending on case activity, so that new evidence is captured automatically as it becomes available. This mirrors how Centreon's scheduled discovery handles dynamic network environments.
- Separate fast indexing from full review. Use the layered approach: let the system filter by metadata first, then pull full documents only for items that pass initial relevance criteria. This keeps review queues manageable.
- Validate with human expertise. Automated classification is accurate but not infallible. Assign a paralegal or attorney to spot-check a percentage of auto-classified documents, particularly in privilege review and Brady material identification.
- Document every configuration decision. Maintain a record of discovery parameters, run dates, and any manual overrides. This documentation supports defensibility if opposing counsel challenges the discovery methodology.
- Coordinate between legal and technical teams. If your firm uses external IT support or a managed service provider, ensure they understand the legal constraints on data handling before granting access to discovery systems.
Selecting the right platform matters as much as the process itself. Tools designed specifically for legal workflows, rather than general IT discovery platforms, embed legal-specific logic like privilege flagging, Brady tracking, and multilingual evidence processing directly into the pipeline.
Key takeaways
Automated discovery reduces legal case processing time from weeks to hours by replacing manual document review with continuous, software-driven classification and retrieval.
| Point | Details |
|---|---|
| Core mechanism | Software scans, classifies, and indexes data using metadata filters before full record retrieval. |
| Three main types | Network discovery, process discovery, and data discovery each serve distinct legal workflow needs. |
| Legal risk management | FRCP 26(b)(3) protections apply, but AI tool names may require disclosure per Morgan v. V2X. |
| Governance is non-negotiable | Defined scopes, scheduled runs, and audit logs prevent scope drift and protect defensibility. |
| Human validation remains critical | Automated classification requires attorney or paralegal spot-checks, especially for privilege review. |
Why I think legal teams underestimate the governance problem
Most conversations about automated discovery in legal practice focus on speed, and the speed gains are real. What gets less attention is the governance layer, and that gap is where I see attorneys create problems for themselves.
The technology works. The failure point is almost always in how discovery jobs are configured and documented. I have seen situations where a well-intentioned paralegal expands a custodian list mid-case without logging the change, and the resulting data set becomes impossible to defend in a meet-and-confer. Opposing counsel does not need to prove the tool was wrong. They only need to show the methodology was inconsistent.
The Morgan v. V2X decision is a useful marker for where courts are heading. Work product protection is available, but it is not automatic, and the disclosure question around specific AI platforms is still being resolved. Attorneys who treat their discovery tools as black boxes are taking on risk they may not recognize until it surfaces in litigation.
The practical answer is not to avoid automation. The answer is to treat discovery configuration with the same discipline you apply to a legal hold notice. Write it down, date it, and keep it in the file. Platforms that build audit logging into the workflow by default, rather than leaving it to the user, are worth prioritizing for exactly this reason.
AI's role in legal discovery will expand significantly over the next few years. The attorneys who benefit most will be those who understand the technical workflow well enough to govern it, not just those who adopt it fastest.
— Faisal
See how Caseflow handles automated discovery for criminal defense
Criminal defense attorneys working with large volumes of discovery materials need more than a general-purpose automation tool. Caseflow combines AI-driven transcription, summarization, and searchable entity extraction in one platform built specifically for legal workflows.
The Brady-trail audit log tracks every action taken on case files, giving you a defensible record of your entire discovery process. Multilingual evidence processing preserves original audio while generating accurate transcripts, and the platform's security architecture is designed to protect attorney-client privilege at every stage. For criminal defense teams that need to move from case file to trial-ready analysis in hours rather than weeks, Caseflow is built for exactly that workflow.
FAQ
What is automated discovery in legal practice?
Automated discovery is the use of software tools to scan, classify, and retrieve case-relevant documents and data without manual review of each item. The process applies predefined rules and AI models to identify relevant materials, flag privileged content, and maintain current inventories as new evidence arrives.
How does automated discovery differ from traditional eDiscovery?
Traditional eDiscovery relies on manual review workflows where attorneys and paralegals individually assess documents for relevance and privilege. Automated discovery uses continuous scanning, metadata indexing, and AI classification to process large document sets faster and with fewer human errors, though human validation remains a required step for defensibility.
Do attorneys need to disclose AI tools used in automated discovery?
Under FRCP 26(b)(3), work product protection can extend to AI-assisted discovery tools, but Morgan v. V2X established that the names of specific AI platforms may require disclosure depending on context and court requirements. Attorneys should review applicable local rules and consult recent case law before assuming full protection.
What are the biggest risks of using automated discovery tools?
Scope drift, inadequate governance, and confidentiality exposure are the three primary risks. Without defined parameters and scheduled runs, discovery systems can collect data outside the intended custodian set, creating defensibility problems. Attorneys must also verify that third-party platforms do not process privileged materials through external pipelines.
How often should automated discovery jobs be scheduled?
Discovery jobs should run on a cadence that matches case activity, typically daily during active production periods and weekly during quieter phases. Continuous or scheduled refreshes prevent silent drift in custodian coverage and capture newly produced evidence without requiring a full manual re-review.